WordPress.com officially lets AI automate content management

Quick Summary
WordPress has officially added support for AI assistants to automatically create and manage content. This major update lets users operate their websites using nothing more than plain natural language commands.
WordPress.com just did what many people have been waiting for
43% of all websites on the internet run on WordPress, and now AI can manage all of them on its own. WordPress.com has officially allowed AI agents to access, edit, and publish content directly on users' websites through the MCP protocol. This is undeniably a massive shift, especially since WordPress only opened MCP for analytics and reporting in 2025.
Previously, updating or writing a new post required too many steps: log in, find the right post, edit each field, then hit save. Using AI meant connecting through third-party tools that were cumbersome to set up. Now you simply tell the AI: "Update the latest post title to X and add this excerpt." The AI edits directly on WordPress and handles the rest without switching to any other platform.
What is MCP and why is it behind all of this?
MCP stands for Model Context Protocol, a protocol that lets AI see and interact with external applications. It was created and backed by Anthropic, which is why it has become the common standard for so many AI developers, giving users confidence in its long-term staying power. MCP differs from a regular API in an important way: if an API is a gateway that lets developers connect two systems together, MCP is a gateway designed specifically for AI, helping language models understand the context of each application rather than just receiving raw data.
WordPress.com deployed MCP late last year, and this new AI agent capability is built entirely on top of that foundation. The key advantage is that you are not locked into one specific AI. You can connect Claude, ChatGPT, Cursor, or any MCP-compatible AI client to the same WordPress.com account. To activate it, visit wordpress.com/mcp, enable the MCP features you want, and AI tools like Claude, Gemini, and ChatGPT will then be able to connect.
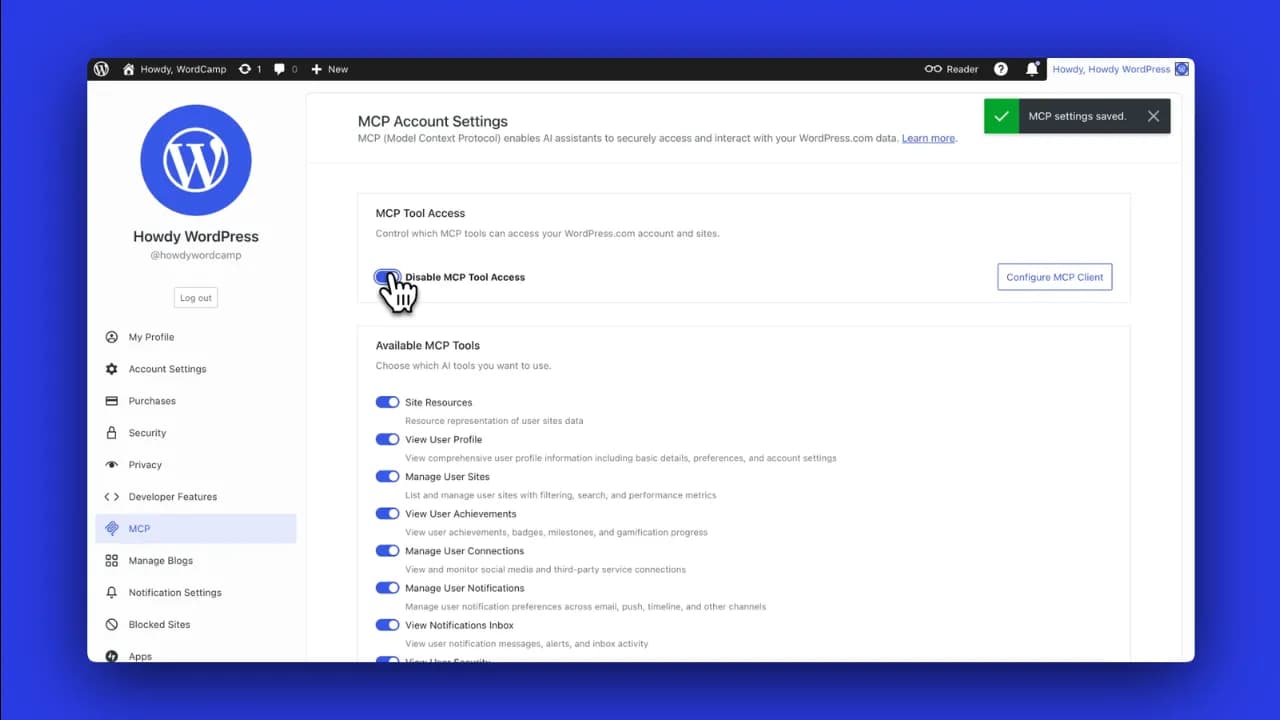
What can an AI agent actually do on WordPress?
The list of supported features is probably longer than you expect. Once connected, you can issue commands in natural language to perform almost anything covered in this MCP update.
Content management: Ask the AI to create a new post, edit a title, add an excerpt, or move a draft to published status and back. The AI can even write a blog post in your usual style and save it as a draft for review before it goes live.
Comment moderation: Approve pending comments, mark spam, delete inappropriate responses, and reply to the latest comment on a specific post, all from a single instruction.
Content organization: The AI can create new categories, add tags to posts, and reorganize your content taxonomy without you having to navigate through each dashboard menu.
Media updates: Fixing alt text on recently uploaded images or updating captions is tedious work when done manually across dozens of posts. The AI handles it in seconds.
Discovery and reporting: Ask which pages get the most traffic, request a summary of recent comments, or get suggestions for ten future post topics based on your existing content.
Bulk cleanup: Delete all drafts older than a year or move a batch of posts from one status to another, tasks that previously required a plugin or manual one-by-one effort.
What to keep in mind before letting AI touch your WordPress site
Convenient as it sounds, giving AI direct edit access to your website is still something worth thinking through carefully. WordPress.com has built in some basic guardrails: AI-generated posts are saved as drafts by default and do not publish automatically, and every change is logged in the Activity Log so you can review it at any time. However, actions like bulk-deleting posts or changing post statuses in bulk have no simple undo mechanism, so commands need to be deliberate and clearly worded before you send them.
On content quality, AI can write posts in your style based on older articles, but "in your style" does not mean the output will match your actual quality. AI-drafted posts still need a human read-through before publishing, especially on specialized topics or anything where accuracy matters. Additionally, features like viewing the user list and checking plugin status are only available to administrator accounts, which is a reasonable limit to prevent unnecessary security risks.
The bigger picture as platforms open up to AI agents
WordPress.com currently handles 20 billion page views and 409 million visitors every month. When the platform powering 43% of the global web officially opens its doors to AI agents, the question is no longer whether AI will change how content is created. The real question is what percentage of the web will be AI-generated content within the next two years.
This trend is accelerating across the board. Meta acquired Moltbook, a social network where AI agents can post and interact, while Anthropic is also testing AI-written blog content under human supervision. WordPress.com is not the first to have this idea, but they are the first to deploy it at a scale large enough to create a real impact.
For everyday users, this move by WordPress brings the barrier to running a website closer to zero. You no longer need to understand how WordPress works. You only need to know what you want and say it. But precisely because the barrier is so low, low-quality content will also spread more freely, and the ability to distinguish what is actually worth reading will become an increasingly important skill for anyone navigating the web. If you are already on WordPress.com, go to WordPress now and start connecting your writing skills to it.



