WordPress.com chính thức cho phép AI tự động hóa nội dung

Tóm tắt nhanh
Nền tảng WordPress chính thức hỗ trợ các trợ lý AI tự động tạo và quản lý nội dung. Cải tiến lớn này giúp người dùng dễ dàng thao tác trên website chỉ bằng các câu lệnh ngôn ngữ tự nhiên cơ bản.
Wordpress.com vừa làm điều mà nhiều người chờ đợi
43% số website trên toàn cầu đang chạy trên Wordpress và giờ đây AI có thể tự mình quản lý tất cả chúng. Wordpress.com vừa chính thức cho phép AI agent truy cập, chỉnh sửa và xuất bản nội dung trực tiếp trên website của người dùng thông qua giao thức MCP. Đây chắc chắn phải là thay đổi cực lớn kể từ khi Wordpress đã mở MCP nhưng chỉ cho phép phân tích và báo cáo về website năm 2025.
Trước đây để cập nhật, viết mới một bài viết, bạn phải dùng quá nhiều thao tac đăng nhập - tìm đúng bài- chỉnh sửa từng trường rồi nhấn lưu, hoặc nếu dùng AI thì phải kết nối qua các công cụ bên thứ ba phải cài đặt khá rắc rối. Giờ thì bạn chỉ cần nhắn cho AI một câu: "Cập nhật tiêu đề bài mới nhất thành X và thêm đoạn trích này vào." AI sẽ chỉnh sửa trực tiếp ở Wordpress và thực hiện hết phần còn lại mà không phải chuyển qua các nền tảng khác.
MCP là gì và nó là thứ đứng sau toàn bộ kết nối?
MCP viết tắt của Model Context Protocol là giao thức giúp AI nhìn thấy và tương tác với các ứng dụng bên ngoài. MCP được ông lớn Anthropic tạo ra và hậu thuẫn cho nên nó đã và đang trở thành chuẩn chung cho rất nhiều nhà phát triển AI cho nên mọi người rất yên tâm về sự lâu dài của nó. MCP khác với API ở chỗ nếu API là cái cổng để lập trình viên kết nối hai hệ thống với nhau thì MCP là cái cổng được thiết kế riêng cho AI, giúp mô hình ngôn ngữ hiểu được ngữ cảnh của từng ứng dụng thay vì chỉ nhận dữ liệu thô.
WordPress.com đã triển khai MCP từ cuối năm ngoái và tính năng AI agent lần này được xây dựng hoàn toàn trên nền tảng đó. Điểm mạnh là bạn không bị gắn chặt với một AI cụ thể mà có thể kết nối Claude, ChatGPT, Cursor hoặc bất kỳ AI client nào hỗ trợ MCP với cùng một tài khoản WordPress.com. Để kích hoạt, chỉ cần truy cập wordpress.com/mcp và phải bật các tính năng MCP mong muốn rồi các AI như Claude, Gemini, ChatGPT mới có thể kết nối được vào MCP.
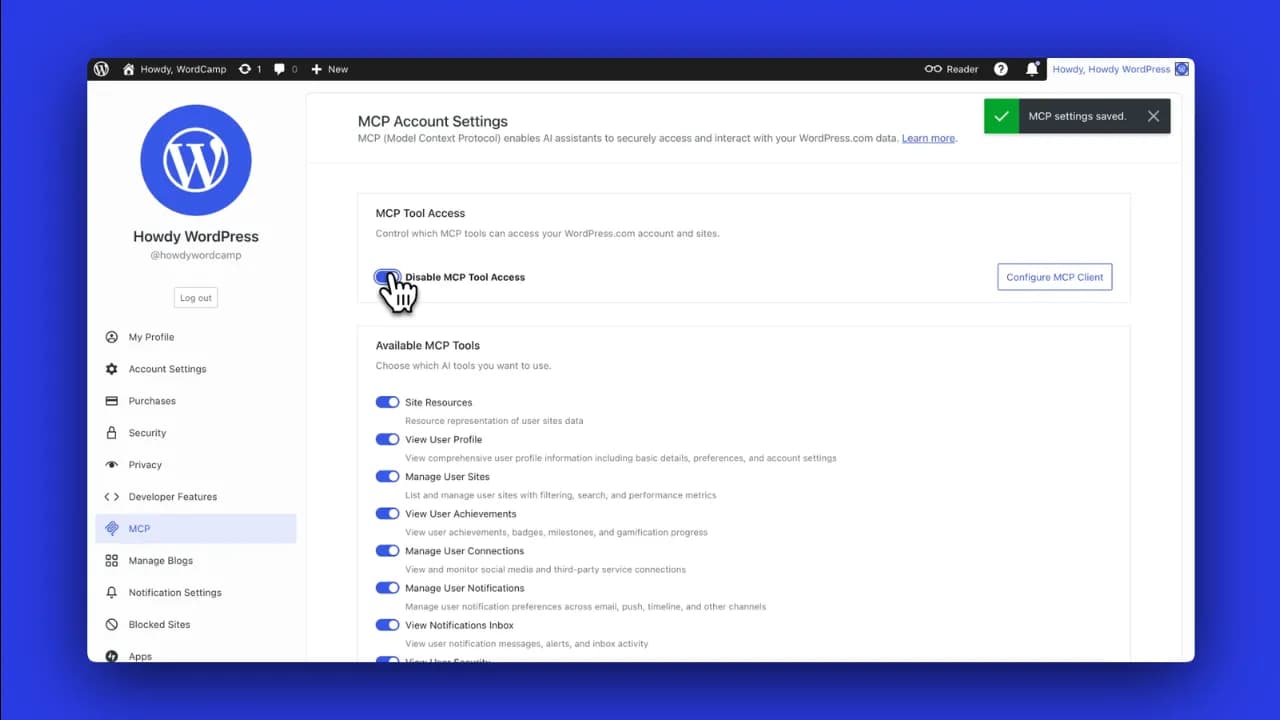
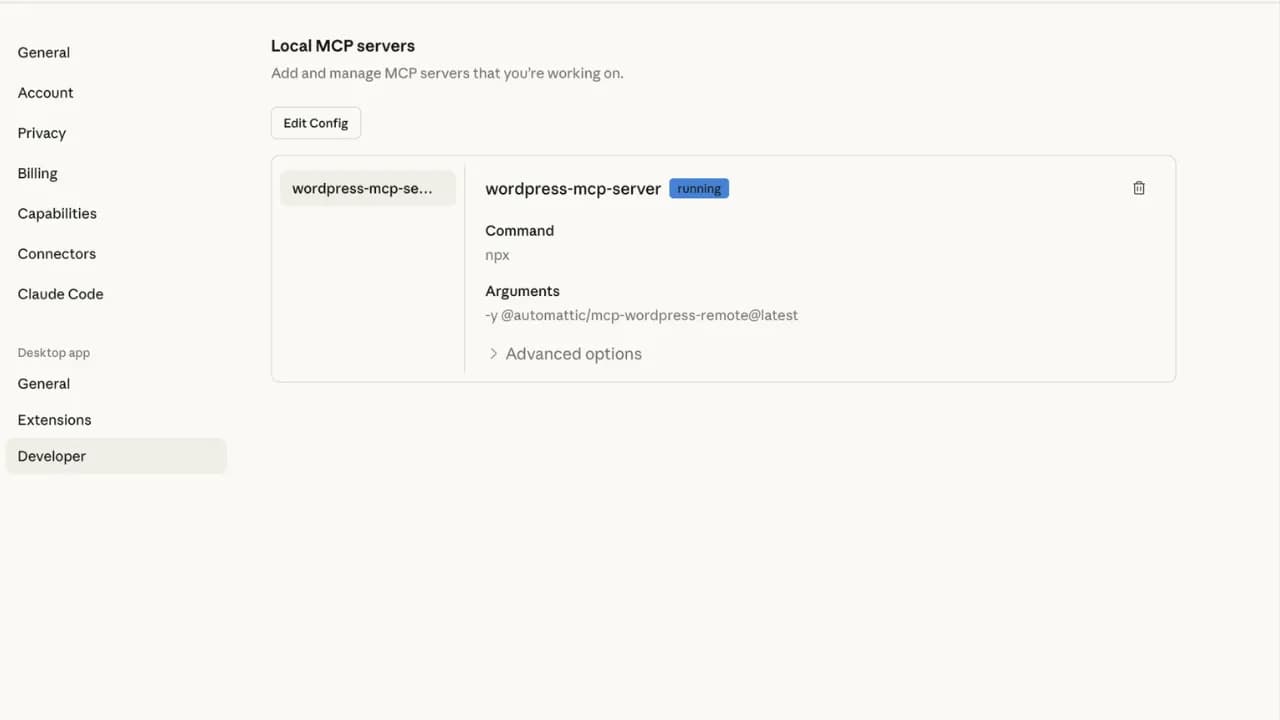
AI agent làm được gì trên Wordpress
Danh sách tính năng Wordpress hỗ trợ chắc chắn dài hơn bạn nghĩ khá nhiều đấy. Tất nhiên sau khi kết nối, bạn có thể ra lệnh bằng ngôn ngữ tự nhiên để thực hiện hầu hết mọi tính năng trong phần cập nhật MCP mới này.
Quản lý nội dung: Bạn có thể yêu cầu AI tạo bài viết mới, chỉnh sửa tiêu đề hoặc thêm đoạn trích hoặc chuyển bản nháp sang trạng thái đã xuất bản và ngược lại. AI thậm chí có thể viết một bài blog theo phong cách thường thấy của bạn rồi lưu dưới dạng bản nháp chờ duyệt trước khi đăng chính thức.
Quản lý bình luận: Bạn có thể duyệt các bình luận đang chờ xử lý, đánh dấu spam, xóa comment không phù hợp và thậm chí trả lời bình luận mới nhất trên một bài cụ thể, tất cả chỉ bằng một câu lệnh.
Tổ chức nội dung: AI có thể tạo danh mục mới, thêm tag vào bài viết và sắp xếp lại cấu trúc phân loại nội dung mà không cần bạn phải mò mẫm qua từng menu trong dashboard.
Cập nhật media: Sửa alt text cho ảnh vừa tải lên hoặc cập nhật chú thích theo tên ảnh là những việc nhỏ nhặt nhưng tốn thời gian nếu làm thủ công trên hàng chục bài viết, và AI xử lý điều này chỉ trong vài giây.
Theo dõi và khám phá: Bạn có thể hỏi trang nào có lượng truy cập nhiều nhất hoặc đơn giản là yêu cầu tóm tắt các bình luận gần đây hoặc đề xuất 10 chủ đề bài viết tiếp theo dựa trên nội dung hiện có của blog.
Dọn dẹp hàng loạt: Xóa tất cả bản nháp đã để quá một năm hoặc chuyển một loạt bài từ trạng thái này sang trạng thái khác là những việc mà trước đây cần plugin hoặc phải làm tay từng bài một.
Cần lưu ý gì trước khi dùng AI cho Wordpress?
Mặc dù nghe có vẻ tiện lợi, trao quyền cho AI chỉnh sửa trực tiếp website vẫn là việc cần suy nghĩ kỹ. Wordpress.com đã xây dựng một số rào chắn cơ bản đó là bài viết do AI tạo mặc định được lưu dưới dạng bản nháp và không tự xuất bản, trong khi mọi thay đổi đều được ghi lại trong Activity Log để bạn có thể kiểm tra lại bất cứ lúc nào. Tuy nhiên với một số tác vụ như xóa bài hàng loạt hay chuyển trạng thái bài viết lại không có cơ chế hoàn tác đơn giản, vì vậy bạn cần kiểm tra kĩ trước khi ra lệnh tất nhiên phải rõ ràng và có chủ đích.
Về chất lượng nội dung, AI có thể viết bài theo phong cách của bạn dựa trên các bài cũ, nhưng "theo phong cách" không có nghĩa là đạt chất lượng tương đương. Bài nháp do AI tạo vẫn cần một lượt đọc lại của con người trước khi đăng, đặc biệt với những chủ đề chuyên sâu hoặc cần độ chính xác cao. Ngoài ra, tính năng xem danh sách người dùng và kiểm tra trạng thái plugin chỉ khả dụng cho tài khoản quản trị viên, đây là giới hạn hợp lý để tránh rủi ro bảo mật không đáng có.
Bức tranh rộng hơn khi các nền tảng mở cửa cho AI agent
Wordpress.com hiện ghi nhận 20 tỷ lượt xem trang và 409 triệu khách truy cập mỗi tháng. Khi nền tảng chiếm 43% web toàn cầu chính thức mở cửa cho AI agent, câu hỏi không còn là liệu AI có thay đổi cách nội dung được tạo ra không? mà là nội dung do AI tạo sẽ chiếm bao nhiêu phần trăm web trong 2 năm tới ?.
Xu hướng này đang diễn ra đồng thời ở nhiều nơi như Meta mua lại Moltbook là mạng xã hội nơi AI agent có thể đăng bài và tương tác, trong khi Anthropic cũng thử nghiệm cho AI viết blog dưới sự giám sát của con người. Wordpress.com không phải người tiên phong về ý tưởng, nhưng họ là người đầu tiên triển khai nó ở quy mô đủ lớn để tạo ra tác động thực sự.
Với người dùng phổ thông động thái của Wordpres giúp rào cản vận hành một website đang tiến gần về 0 và bạn không cần biết Wordpress hoạt động như thế nào mà chỉ cần biết mình muốn gì rồi nói ra điều đó. Tuy nhiên chính vì rào cản thấp, nội dung kém chất lượng cũng sẽ xuất hiện tràn lan và khả năng phân biệt nội dung đáng đọc sẽ ngày càng trở thành kỹ năng quan trọng của người dùng web. Nếu bạn đang dùng Wordpress.com, hãy thử truy cập Wordpress và bắt đầu sử dụng các skils viết bài của mình để kết nối tới Wordpress ngay.



