Claude Code tự điều phối công việc với Dynamic Workflows

Tóm tắt nhanh
Thariq Shihipar từ team Claude Code tại Anthropic vừa công bố Dynamic Workflows, tính năng cho phép Claude tự thiết kế quy trình làm việc thay vì chỉ chờ lệnh. Tính năng này giải quyết ba lỗi chí mạng của AI agent: lười biếng tác nhân (Agentic Laziness), thiên vị bản thân (Self-Preferential Bias) và trôi mục tiêu (Goal Drift). Thay vì tăng trí thông minh thô của model, Anthropic xây dựng ràng buộc kiến trúc vào quy trình, cho phép Claude viết harness JavaScript tùy chỉnh, cô lập ngữ cảnh cho sub-agent và áp dụng sáu mẫu điều phối có thể tái sử dụng. Bài viết thu hút hơn 22.000 bookmark trong 3 ngày.
Bài đăng của Thariq Shihipar từ team Claude Code đã gây chú ý lớn trong cộng đồng sử dụng AI. Anh ấy tiết lộ Dynamic Workflows, tính năng cho phép Claude tự thiết kế quy trình làm việc thay vì chỉ chờ lệnh, và đây được coi là bản nâng cấp quan trọng nhất kể từ khi Claude Code có skills và subagents. Tính năng này là khái niệm harness làm bản chất để giải thích các yêu cầu kĩ thuật.
Ba lỗi chí mạng nào khiến AI agent thất bại ở nhiệm vụ phức tạp
Trước khi nói về giải pháp, Thariq chỉ ra một thực tế khó chịu: hầu hết AI agent hiện nay đều gặp vấn đề nghiêm trọng khi xử lý nhiệm vụ phức tạp, đa bước trong một cửa sổ ngữ cảnh duy nhất. Ông phân loại chúng thành ba dạng thất bại cốt lõi mà gần như mọi hệ thống agent đều mắc phải.
Khi AI lười biếng bằng cách tự tuyên bố xong dù mới làm nửa việc
Đây là hiện tượng Agentic Laziness, khi agent thực hiện một phần công việc rồi tự báo cáo là đã hoàn thành. Ví dụ cụ thể: bạn yêu cầu agent review 50 file code, nhưng nó chỉ xem qua 20 file rồi kết luận rằng mọi thứ ổn. Nguyên nhân nằm ở giới hạn cửa sổ ngữ cảnh, khi lượng thông tin quá lớn, agent có xu hướng đi tắt để hoàn thành nhanh hơn.
Agent sẽ tự thiên vị bản thân nó đúng không
Agent tự thiên thị nó gọi là Self-Preferential Bias, điều này xảy ra khi bạn yêu cầu agent kiểm tra lại kết quả của chính nó. Giống như nhờ một học sinh tự chấm bài thi, agent có xu hướng nghiêng về phía kết quả mà nó đã tạo ra, dẫn đến xác nhận thiếu phê phán và bỏ qua các lỗi tiềm ẩn. Điều này đặc biệt nguy hiểm trong các nhiệm vụ đòi hỏi độ chính xác cao.
Làm sao để agent không mất dần ý định ban đầu qua mỗi bước
Hiện tượng trôi mất mục tiêu (Goal Drift) là hiện tượng agent dần quên mục tiêu ban đầu sau nhiều bước xử lý hoặc sau quá trình nén ngữ cảnh (context compaction). Những ràng buộc cụ thể như "không làm X" hoặc các trường hợp quan trọng có thể bị loại bỏ khi bộ nhớ bị tóm tắt lại vì vậy kết quả cuối cùng lệch khỏi yêu cầu gốc mà agent không hề nhận ra.
Dynamic Workflows giúp Claude tự viết bộ khung điều phối công việc
Giải pháp của Anthropic không phải là làm model thông minh hơn, mà là thay đổi cách Claude tổ chức công việc. Dynamic Workflows biến Claude từ agent viết code thành agent thiết kế quy trình vận hành cho công việc phức tạp. Khái niệm cốt lõi ở đây là tự tổ chức (self-organization): Claude có thể tự phân tích mục tiêu, chọn chế độ làm việc phù hợp và tạo ra quy trình nội bộ trước khi bắt tay vào thực hiện.
Harness tùy chỉnh thay vì quy trình cố định
Thay vì hoạt động trong một môi trường cố định, Claude viết một bộ khung harness bằng JavaScript được thiết kế riêng cho từng nhiệm vụ. Harness này đóng vai trò như một quản lý dự án: nó chia nhỏ công việc, khởi tạo các sub-agent chuyên biệt cho từng phần, chỉ định công cụ phù hợp, định tuyến công việc đến các model khác nhau và thực hiện xác minh đối kháng (adversarial verification) để đảm bảo chất lượng.
Harness hoạt động như thế nào?
Để hiểu rõ hơn, hãy hình dung harness như một kịch bản sân khấu mà Claude tự soạn trước khi diễn. Khi nhận được một nhiệm vụ phức tạp, Claude không lao vào làm ngay mà dừng lại để viết một đoạn JavaScript mô tả toàn bộ quy trình: cần bao nhiêu sub-agent, mỗi agent làm gì, thứ tự thực hiện ra sao và kết quả từ agent này được chuyển cho agent kia như thế nào.
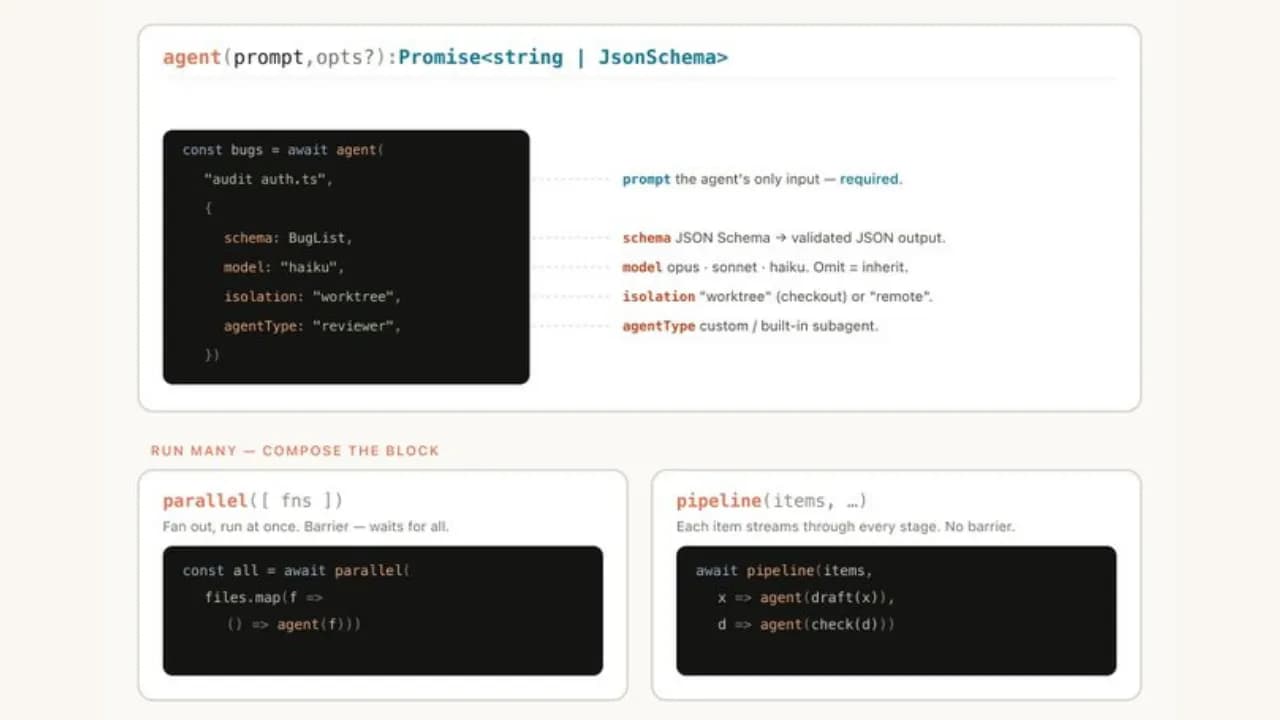
Ví dụ cụ thể: nếu bạn yêu cầu Claude audit 1.000 tin nhắn Slack để tìm sự cố lặp lại, harness có thể trông như thế này về mặt logic:
- Agent 1 (phân loại): đọc toàn bộ tin nhắn và gán nhãn theo chủ đề
- Agent 2, 3, 4 (xử lý song song): mỗi agent phân tích sâu một nhóm chủ đề riêng
- Agent 5 (tổng hợp): gom kết quả từ ba agent trên, loại bỏ trùng lặp
- Agent 6 (kiểm tra chéo): đọc lại kết quả tổng hợp và phản biện độc lập
Điểm quan trọng là Claude viết harness này dựa trên đặc điểm cụ thể của từng nhiệm vụ, không phải theo một khuôn mẫu cứng nhắc. Nhiệm vụ khác nhau sẽ cho ra harness khác nhau, và đó chính là lý do tính năng này được gọi là "dynamic".
Cô lập ngữ cảnh để ngăn sự suy thoái của ngữ cảnh
Một trong những thiết kế thông minh nhất của Dynamic Workflows là tính năng Isolation. Mỗi sub-agent được cấp cửa sổ ngữ cảnh riêng biệt, hoàn toàn độc lập với các agent khác. Điều này ngăn chặn hiện tượng suy thoái ngữ cảnh (context rot) tức sự suy giảm chất lượng khi ngữ cảnh bị quá tải, đồng thời triệt tiêu cả Agentic Laziness lẫn Goal Drift vì mỗi agent chỉ tập trung vào phần việc nhỏ được giao.
Sáu mẫu điều phối có thể tái sử dụng
Claude có thể kết hợp sáu mẫu điều phối sẵn có để xử lý đa dạng tình huống:
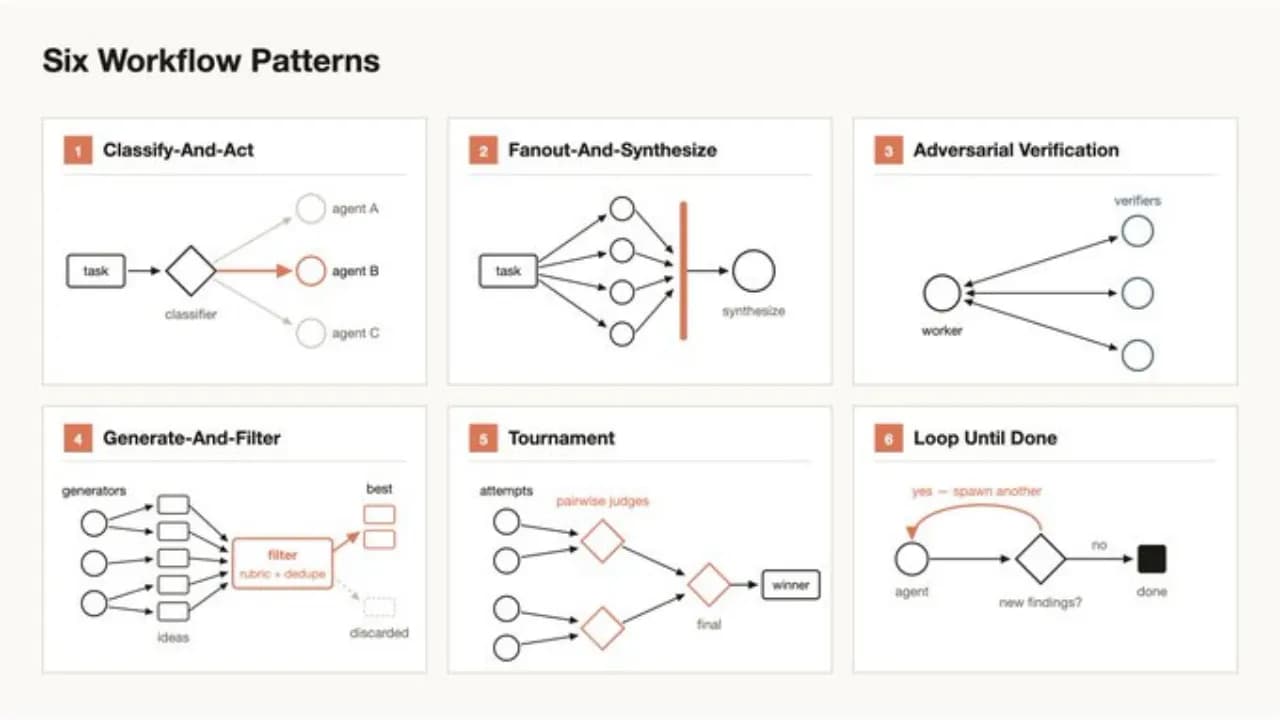
- Phân loại và hành động: phân loại đầu vào rồi chọn hành động phù hợp
- Phân chi và tổng hợp: chia công việc ra nhiều nhánh song song rồi tổng hợp kết quả
- Kiểm tra chéo: dùng agent khác kiểm tra chéo kết quả
- Tạo và lọc: tạo nhiều phương án rồi lọc ra phương án tốt nhất
- Tạo ra giải đấu: cho các phương án "đấu đối khảng trực tiếp với nhau rồi loại dần
- Vòng lặp: lặp lại cho đến khi đạt tiêu chuẩn chất lượng
Có thể tối ưu chi phí khi sử dụng Dynamic Workflows không
Chạy nhiều sub-agent song song nghe có vẻ tốn kém, nhưng thực tế Dynamic Workflows được thiết kế để tối ưu chi phí theo một số cách cụ thể.
Định tuyến thông minh đến model phù hợp
Không phải mọi bước trong quy trình đều cần model mạnh nhất. Harness cho phép Claude định tuyến từng tác vụ đến model phù hợp với độ phức tạp của nó: các bước phân loại đơn giản có thể chạy trên model nhỏ hơn và rẻ hơn, trong khi chỉ những bước đòi hỏi suy luận sâu mới cần đến model lớn. Kết quả là tổng chi phí thường thấp hơn so với việc chạy toàn bộ quy trình trên một model duy nhất.
Cô lập ngữ cảnh giúp giảm token tiêu thụ
Vì mỗi sub-agent chỉ nhận đúng phần ngữ cảnh cần thiết cho công việc của mình, tổng lượng token tiêu thụ trên toàn bộ quy trình thường thấp hơn đáng kể so với cách tiếp cận truyền thống, khi toàn bộ lịch sử hội thoại được nhồi vào một cửa sổ ngữ cảnh duy nhất ngày càng phình to.
Tránh làm lại công việc nhờ kiểm tra lại sớm
Harness có thể cài các điểm kiểm tra chất lượng (checkpoint) giữa các bước. Nếu một bước cho ra kết quả không đạt yêu cầu, hệ thống dừng và xử lý lại đúng bước đó thay vì chạy tiếp toàn bộ quy trình rồi mới phát hiện lỗi ở cuối. Cách này tiết kiệm đáng kể chi phí cho các tác vụ dài nhiều bước.
Ứng dụng thực tế của Dynamic Workflow như thế nào
Điều khiến Thariq hào hứng nhất không phải là khả năng code, mà là việc Dynamic Workflows mở rộng Claude Code sang các nhiệm vụ phi kỹ thuật. Tính năng này có thể kích hoạt bằng ngôn ngữ tự nhiên (ví dụ: "use a workflow") hoặc từ khóa "ultracode." Các ứng dụng thực tế bao gồm:
- Audit hàng nghìn tin nhắn trên Slack để tìm sự cố lặp lại
- Xếp hạng và sàng lọc bộ hồ sơ ứng viên lớn một cách có hệ thống
- Chạy giải đấu loại trực tiếp tự động để chọn tên tốt nhất cho CLI tool
- Xử lý các nhiệm vụ vận hành đòi hỏi độ chính xác cao mà trước đây chỉ con người mới làm được
Triết lý thiết kế là ràng buộc kiến trúc thay vì trí tuệ thô
Điểm đáng chú ý nhất trong cách tiếp cận của Anthropic là triết lý thiết kế: thay vì cố gắng tăng trí thông minh thô của model, họ xây dựng các ràng buộc kiến trúc (architectural constraints) vào quy trình làm việc. Nói cách khác, thay vì hy vọng model tự biết cách tránh lỗi, họ thiết kế hệ thống sao cho lỗi khó xảy ra ngay từ đầu, và harness chính là công cụ thực thi triết lý đó.
Dynamic Workflows cho thấy bước tiến tiếp theo của AI agent không nằm ở model thông minh hơn mà ở khả năng tự thiết kế quy trình. Giống cách một quản lý giỏi phân chia công việc cho đội ngũ thay vì tự làm tất cả, Claude giờ đây có thể tự tổ chức đội ngũ sub-agent của mình, và đây là tín hiệu rõ ràng rằng tương lai của AI coding không chỉ còn là viết code nhanh hơn mà là tổ chức công việc tốt hơn.



